Pot do izkušenega in uspešnega programerja je težka, a zagotovo dosegljiva. Podatkovne strukture so osrednja komponenta, ki jo mora obvladati vsak študent programiranja, in verjetno ste se morda že naučili ali delali z nekaterimi osnovnimi podatkovnimi strukturami, kot so nizi ali seznami.
Anketarji raje postavljajo vprašanja, povezana s podatkovnimi strukturami, zato, če se pripravljate na razgovor za službo, boste morali osvežiti svoje znanje o podatkovnih strukturah. Berite naprej, ko navajamo najpomembnejše podatkovne strukture za programerje in razgovore za službo.
Povezani seznami so ena najosnovnejših struktur podatkov in pogosto izhodišče za študente pri večini predmetov podatkovnih struktur. Povezani seznami so linearne podatkovne strukture, ki omogočajo zaporedni dostop do podatkov.
Elementi znotraj povezanega seznama so shranjeni v posameznih vozliščih, ki so povezana (povezana) s kazalci. Povezani seznam si lahko predstavljate kot verigo vozlišč, povezanih med seboj prek različnih kazalcev.
Povezano: Uvod v uporabo povezanih seznamov v Javi
Preden se poglobimo v posebnosti različnih vrst povezanih seznamov, je ključnega pomena razumeti strukturo in izvedbo posameznega vozlišča. Vsako vozlišče na povezanem seznamu ima vsaj en kazalec (dvojno povezana vozlišča seznama imajo dva kazalca), ki ga poveže z naslednjim vozliščem na seznamu in samo podatkovno postavko.
Vsak povezan seznam ima glavno in repno vozlišče. Eno-povezana vozlišča seznama imajo samo en kazalec, ki kaže na naslednje vozlišče v verigi. Poleg naslednjega kazalca imajo vozlišča dvojno povezanih seznamov še en kazalec, ki kaže na prejšnje vozlišče v verigi.
Vprašanja pri intervjuju, povezana s povezanimi seznami, se običajno vrtijo okoli vstavljanja, iskanja ali brisanja določenega elementa. Vstavljanje v povezan seznam traja O(1) časa, brisanje in iskanje pa lahko v najslabšem primeru O(n) časa. Povezani seznami torej niso idealni.
2. Binarno drevo
Binarna drevesa so najbolj priljubljena podmnožica podatkovne strukture drevesne družine; elementi v binarnem drevesu so razporejeni v hierarhiji. Druge vrste dreves vključujejo AVL, rdeče-črna, B drevesa itd. Vozlišča binarnega drevesa vsebujejo podatkovni element in dva kazalca na vsako podrejeno vozlišče.
Vsako nadrejeno vozlišče v binarnem drevesu ima lahko največ dve podrejeni vozlišči, vsako nadrejeno vozlišče pa je lahko nadrejeno za dve vozlišči.
Povezano: Vodnik za začetnike po binarnih drevesih
Binarno iskalno drevo (BST) shranjuje podatke v razvrščenem vrstnem redu, kjer elementi z vrednostjo ključ/vrednost manjšo od nadrejenega vozlišče je shranjeno na levi, elementi z večjo vrednostjo ključ/vrednost od nadrejenega vozlišča pa so shranjeni na prav.
Binarna drevesa se običajno sprašujejo v intervjujih, zato če se pripravljate na intervju, bi morali vedeti, kako sploščiti binarno drevo, poiskati določen element in še več.
3. Hash tabela
Hash tabele ali zgoščeni zemljevidi so zelo učinkovita podatkovna struktura, ki shranjuje podatke v obliki matrike. Vsakemu podatkovnemu elementu je v hash tabeli dodeljena edinstvena indeksna vrednost, ki omogoča učinkovito iskanje in brisanje.
Postopek dodeljevanja ali preslikave ključev v zgoščevalnem zemljevidu se imenuje zgoščevanje. Učinkovitejša kot je hash funkcija, boljša je učinkovitost same hash tabele.
Vsaka hash tabela shranjuje podatkovne elemente v paru vrednost-indeks.
Kjer je vrednost podatki, ki jih je treba shraniti, indeks pa je edinstveno celo število, ki se uporablja za preslikavo elementa v tabelo. Hash funkcije so lahko zelo zapletene ali zelo preproste, odvisno od zahtevane učinkovitosti zgoščevalne tabele in od tega, kako boste reševali kolizije.
Kolizije pogosto nastanejo, ko zgoščena funkcija ustvari isto preslikavo za različne elemente; Kolzijske preslikave je mogoče razrešiti na različne načine, z uporabo odprtega naslavljanja ali veriženja.
Hash tabele ali zemljevidi hash imajo številne različne aplikacije, vključno s kriptografijo. So prva izbira podatkovne strukture, ko je potrebno vstavljanje ali iskanje v konstantnem času O(1).
4. Skladi
Zborniki so ena izmed enostavnejših podatkovnih struktur in jih je precej enostavno obvladati. Podatkovna struktura sklada je v bistvu vsak resnični sklad (pomislite na kup škatel ali plošč) in deluje na način LIFO (Last In First Out).
Lastnost Stacks LIFO pomeni, da bo prvi dostopen element, ki ste ga nazadnje vstavili. Ne morete dostopati do elementov pod zgornjim elementom v skladu, ne da bi iztaknili elemente nad njim.
Skladi imajo dve primarni operaciji – potiskanje in izpiranje. Push se uporablja za vstavljanje elementa v sklad, pop pa odstrani najvišji element iz sklada.
Imajo tudi veliko uporabnih aplikacij, zato je zelo pogosto, da anketarji postavljajo vprašanja v zvezi s skladi. Znanje obrniti sklad in ovrednotiti izraze je zelo pomembno.
5. Čakalne vrste
Čakalne vrste so podobne skladom, vendar delujejo na način FIFO (First In First Out), kar pomeni, da lahko dostopate do elementov, ki ste jih vstavili prej. Podatkovno strukturo čakalne vrste lahko vizualiziramo kot katero koli realno čakalno vrsto, kjer so ljudje pozicionirani glede na njihov vrstni red prihoda.
Operacija vstavljanja čakalne vrste se imenuje enqueue, brisanje/odstranjevanje elementa z začetka čakalne vrste pa se imenuje razvrščanje v čakalno vrsto.
Povezano: Vodnik za začetnike za razumevanje čakalnih vrst in prednostnih čakalnih vrst
Prednostne čakalne vrste so sestavni del uporabe čakalnih vrst v številnih pomembnih aplikacijah, kot je razporejanje CPE. V prednostni čakalni vrsti so elementi razvrščeni glede na njihovo prednost in ne po vrstnem redu prihoda.
6. Kupe
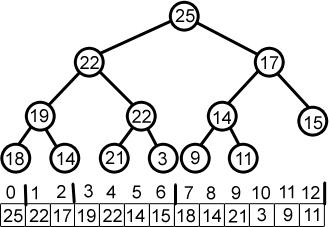
Kupi so vrsta binarnega drevesa, kjer so vozlišča razporejena v naraščajočem ali padajočem vrstnem redu. V Min Heap je ključna vrednost nadrejenega ključa enaka ali manjša od vrednosti njegovih podrejenih, korensko vozlišče pa vsebuje najmanjšo vrednost celotnega kopice.
Podobno korensko vozlišče največje kopice vsebuje največjo vrednost ključa kopice; lastnost kopice morate ohraniti v celotnem kupu.
Povezano: Kupe vs. Skladi: kaj jih loči?
Kupe imajo veliko aplikacij zaradi svoje zelo učinkovite narave; predvsem se prednostne čakalne vrste pogosto izvajajo prek kopic. So tudi osrednja komponenta v algoritmih heapsort.
Naučite se podatkovnih struktur
Podatkovne strukture se lahko sprva zdijo mučne, vendar vzamejo dovolj časa in našli jih boste enostavno kot pita.
So pomemben del programiranja in skoraj vsak projekt jih bo zahteval, da jih uporabite. Pomembno je vedeti, katera podatkovna struktura je idealna za določen scenarij.
Ti algoritmi so bistveni za potek dela vsakega programerja.
Preberite Naprej
- Programiranje
- Analiza podatkov
- Nasveti za kodiranje

Fahad je pisatelj pri MakeUseOf in trenutno študira računalništvo. Kot navdušen pisatelj tehnologij skrbi, da ostane na tekočem z najnovejšo tehnologijo. Še posebej ga zanimata nogomet in tehnologija.
Naročite se na naše novice
Pridružite se našemu glasilu za tehnične nasvete, ocene, brezplačne e-knjige in ekskluzivne ponudbe!
Kliknite tukaj, da se naročite