Oglas
Ali verjamete v idejo, da se enkrat, ko je nekaj objavljeno na internetu, objavi za vedno? No, danes bomo razbremenili ta mit.
Resnica je, da je v mnogih primerih povsem mogoče izkoreniniti podatke z interneta. Seveda obstaja zapis spletnih strani, ki so bile izbrisane, če iščete Wayback stroj, prav? Ja, absolutno. Na Wayback Machine so zapisi spletnih strani, ki se vračajo več let - strani, ki jih ne boste našli z Googlovim iskanjem, ker spletna stran ne obstaja več. Nekdo jo je izbrisal ali se je spletno mesto ustavilo.
Torej, tega ni mogoče zaobiti, kajne? Informacije se bodo za vedno vtisnile v kamen interneta, ki ga bodo generacije lahko videle? No, ne ravno.
Resnica je, da je sicer težko ali nemogoče izbrisati pomembne novice, ki so se z enega spletnega mesta ali spletnega dnevnika razširile na drugega kot virus, Pravzaprav je povsem enostavno izbrisati spletno stran ali več spletnih strani iz vseh zapisov o obstoju - odstraniti to stran tako za iskalnike kot tudi the Wayback stroj
Novi Wayback omogoča vizualno potovanje nazaj v internetni časZdi se, da so se od lansiranja Wayback Machine leta 2001 lastniki spletnega mesta odločili, da bodo vrgli hrbtni del Alexa in ga prenovili z lastno odprto kodo. Po izvedbi testov z ... Preberi več . Seveda je ulov, vendar bomo prišli do tega.3 načine za odstranitev spletnih strani spletnega dnevnika
Prva metoda je tista, ki jo uporablja večina lastnikov spletnih mest, saj ne poznajo ničesar bolje - preprosto brisanje spletnih strani. To se lahko zgodi, ker ste ugotovili, da imate na svojem spletnem mestu podvojeno vsebino ali ker imate stran, ki je ne želite prikazati v rezultatih iskanja.
Preprosto izbrišite stran
Težava s popolnim brisanjem strani s spletnega mesta je v tem, da ste stran že ustvarili na Neto, verjetno obstajajo povezave z vašega lastnega spletnega mesta, pa tudi zunanje povezave z drugih strani do tega stran. Ko ga izbrišete, Google takoj prepozna vašo stran kot manjkajočo stran.

Torej s črtanjem strani niste ustvarili samo težave z napakami pri iskanju »Ne najdem«, ampak ste ustvarili težavo tudi za vse, ki ste kdaj povezali stran. Ponavadi bodo uporabniki, ki pridejo na vaše spletno mesto po eni od teh zunanjih povezav, videli vašo stran 404, kar ni Če imate uporabne predloge za uporabnike, lahko uporabite nekaj, kot je Googlova koda 404 po meri alternative. Toda menite, da bi lahko obstajali bolj graciozni načini brisanja strani iz rezultatov iskanja, ne da bi odstranili vse 404 za obstoječe dohodne povezave, kajne?
No, obstajajo.
Odstranite stran iz Googlovih rezultatov iskanja
Najprej morate razumeti, da če spletna stran, ki jo želite odstraniti iz Googlovih rezultatov iskanja, ni stran z vašega spletnega mesta, potem nimate sreče, razen če obstajajo pravni razlogi ali če je spletno mesto vaše osebne podatke objavilo brez spleta dovoljenje. V tem primeru uporabite Googlove odpravljanje težav pri odstranjevanju da pošljete zahtevo, da se stran odstrani iz rezultatov iskanja. Če imate veljaven primer, boste morda z uspehom odstranili stran - seveda boste morda imeli še večji uspeh kontaktiranje lastnika spletnega mesta Kako odstraniti lažne osebne podatke v internetuSpletna zasebnost ni več zagotovljena. Preberite, kako prijaviti spletno mesto in odstraniti osebne podatke iz interneta. Preberi več kot sem opisal, kako to storiti leta 2009.
Če je stran, ki jo želite odstraniti iz rezultatov iskanja, na svojem spletnem mestu, imate srečo. Vse, kar morate storiti, je ustvariti robots.txt datoteko in se prepričajte, da niste onemogočili niti določene strani, ki je ne želite v rezultatih iskanja, ali celotnega imenika z vsebino, ki jo ne želite indeksirati. Tukaj je opisano, kako izgleda blokada ene strani.
Uporabniški agent: * Onemogoči: /my-deleted-article-that-i-want-removed.html
Bote lahko preprečite tako, da bi preiskal celotne imenike vašega spletnega mesta na naslednji način.
Uporabniški agent: * Onemogoči: / vsebina-o-osebni-stvari /
Google ima odlično stran za podporo s pomočjo katerega lahko ustvarite datoteko robots.txt, če je še niste ustvarili. To deluje izredno dobro, kot sem razložil nedavno v članku o strukturiranje sindikalnih poslov Kako se pogajate o ponudbah za posredovanje in zaščitite svoje uvrstitve v iskalnem omrežjuSindikiranje je v teh dneh ves bes. Nenadoma pa bi lahko ugotovili, da je v rezultatih iskanja zgodba, ki ste jo sprva napisali, sindikalni partner višji od vas. Zaščitite svoje uvrstitve v iskanju. Preberi več da vas ne bodo poškodovali (prosite sindikalne partnerje, da ne dovolijo indeksiranja njihovih strani, kjer ste združeni). Ko se je moj lastni partner za posredovanje strinjal s tem, so strani, ki so bile podvojene vsebine iz mojega bloga, popolnoma izginile iz seznamov iskanja.

Na glavnem spletnem mestu je le tretje mesto za stranjo, kjer so našteli naš naslov, moj blog pa je zdaj naveden tako na prvem kot na drugem mestu; nekaj, kar bi bilo skoraj nemogoče, če bi spletno mesto višjih organov podvojeno stran pustilo indeksirano.
Mnogi se ne zavedajo, da je to mogoče doseči tudi z internetnim arhivom (Wayback Machine). Tu so vrstice, ki jih morate dodati v datoteko robots.txt, da se zgodi.
Uporabniško sredstvo: ia_archiver. Prekini: / vzorčna kategorija /
V tem primeru pravim spletnemu arhivu, naj odstrani karkoli v podimeniku vzorčne kategorije na svojem spletnem mestu iz Wayback Machine. Internetni arhiv razlaga, kako to storiti na njihovi strani za pomoč o izključitvi. Tu pojasnjujejo, da "Internetnega arhiva ne zanima dostopa do spletnih strani ali drugih internetnih dokumentov, katerih avtorji ne želijo svojih gradiv v zbirki."
To je v nasprotju s splošno veljavnim prepričanjem, da se vse, kar je objavljeno na internetu, pometa v arhiv za vedno. Ne - spletnim skrbnikom, ki imajo vso vsebino, je lahko vsebina posebej odstranjena iz arhiva s pristopom robots.txt.
Odstranite posamezno stran z Meta oznakami
Če imate samo nekaj posameznih strani, ki jih želite odstraniti iz rezultatov iskanja Google, vam dejansko ni treba uporabljati pristopa robots.txt Sploh lahko preprosto dodate pravilno metaoznako »roboti« na posamezne strani in robotom naročite, naj ne indeksirajo in ne sledijo povezavam na celotni strani stran.
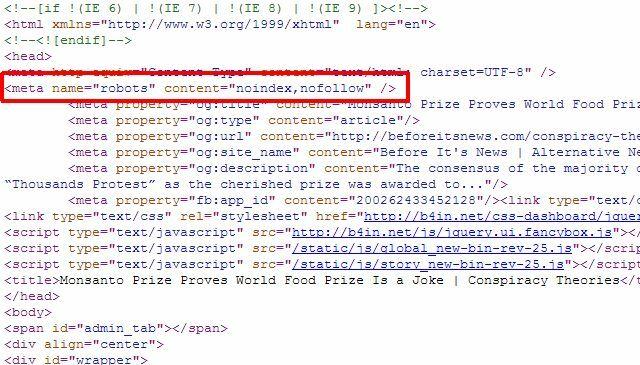
Zgoraj lahko uporabite »robote«, če želite robotom preprečiti indeksiranje strani, ali pa Googlovemu robotu posebej. ne indeksirati, tako da je stran odstranjena samo iz Googlovih rezultatov iskanja, do nje pa lahko še vedno dostopajo drugi iskalni roboti vsebino.
Odvisno je od vas, kako želite upravljati, kaj roboti počnejo s stranjo in ali se stran uvrsti na seznam. Za le nekaj posameznih strani je to morda boljši pristop. Če želite odstraniti celoten imenik vsebine, pojdite z metodo robots.txt.
Ideja o "odstranjevanju" vsebine
Ta vrsta obrača celotno predstavo o "brisanju vsebine iz interneta". Če tehnično odstranite vse lastne povezave do strani na svojem spletnem mestu in jo odstranite iz Iskanja Google in Internetni arhiv s tehniko robots.txt, stran je za vse namene in namene "izbrisana" iz interneta. Kul je, da če na stran obstajajo obstoječe povezave, bodo te povezave še vedno delovale in za te obiskovalce ne boste sprožili 404 napak.
To je bolj "nežen" pristop k odstranjevanju vsebin iz interneta, ne da bi v celoti zmešali obstoječo povezavo vaše spletne strani po internetu. Na koncu odvisno od tega, kako se boste lotili upravljanja vsebine, ki jo zbirajo iskalniki in internetni arhiv, vendar vedno ne pozabite, da je kljub temu, kar ljudje govorijo o življenjski dobi stvari, ki so objavljene na spletu, resnično povsem znotraj vašega nadzor.
Ryan ima diplomo iz elektrotehnike. 13 let je delal v avtomatizacijskem inženiringu, 5 let v IT, zdaj pa je inženir Apps. Nekdanji glavni urednik MakeUseOf je govoril na nacionalnih konferencah o vizualizaciji podatkov in je bil predstavljen na nacionalni televiziji in radiu.